
Return of the V
The Greatest Software Framework Never Used – Part Two of Two


This is an essay on how we write software today. Part One (previously released) described the pre-eminence of Agile methods, and how they have overtaken V-model frameworks for a large majority of software projects. Here in Part Two we survey the software landscape through an Agile lens, and re-discover the need for some basic information that must be documented. Six pieces of information are defined as must-haves even for lean and Agile projects. Some solutions are proposed to manage minimalist V-models in an Agile world; and some non-agile considerations are also listed.
A Minimal Information Approach
Let’s take literally a point from the Agile Manifesto, and state that we prioritize working code over documentation. It leads to an interesting question.
What is the minimum set of information that must be defined in a software project?
To answer this question, lets hypothesize a relatively small software project. Maybe we can think like a mathematician or a philosopher, and use first principles to derive such a set minimum set if information for our project. We’ll start from a ‘zero information’ state; a kind of purist condition with zero documentation. Then we’ll add only what’s absolutely necessary, and see how it goes.
So, in our hypothetical small software project, we deliver software right? Assuming it gets done, then the software itself is created. Therefore the first piece of information necessary in the project is the software itself.
As a product, software is intended to perform some function. In our hypothetical small software project, did we achieve this function or not? We don’t know unless we test it. Therefore, we need test information; specifically test cases and test data, to verify that the code works.
So even in our minimalist world, we have at least two pieces of information: we have the code itself and we have test information related to the code. But what exactly are these tests? What are we testing when we test our software? Well… that depends. It depends on what this software is trying to be; what it’s trying to do. The objective of the software is to perform whatever function we wanted; and probably to exhibit some characteristics like reliable bug-free operation, timing behavior, ability to handle faults, etc. We need some statements, like “the code is supposed to do X, Y, Z, etc.”
This is the role of requirements; which are simply statements of what the software shall do in order to be considered complete and/or correct.
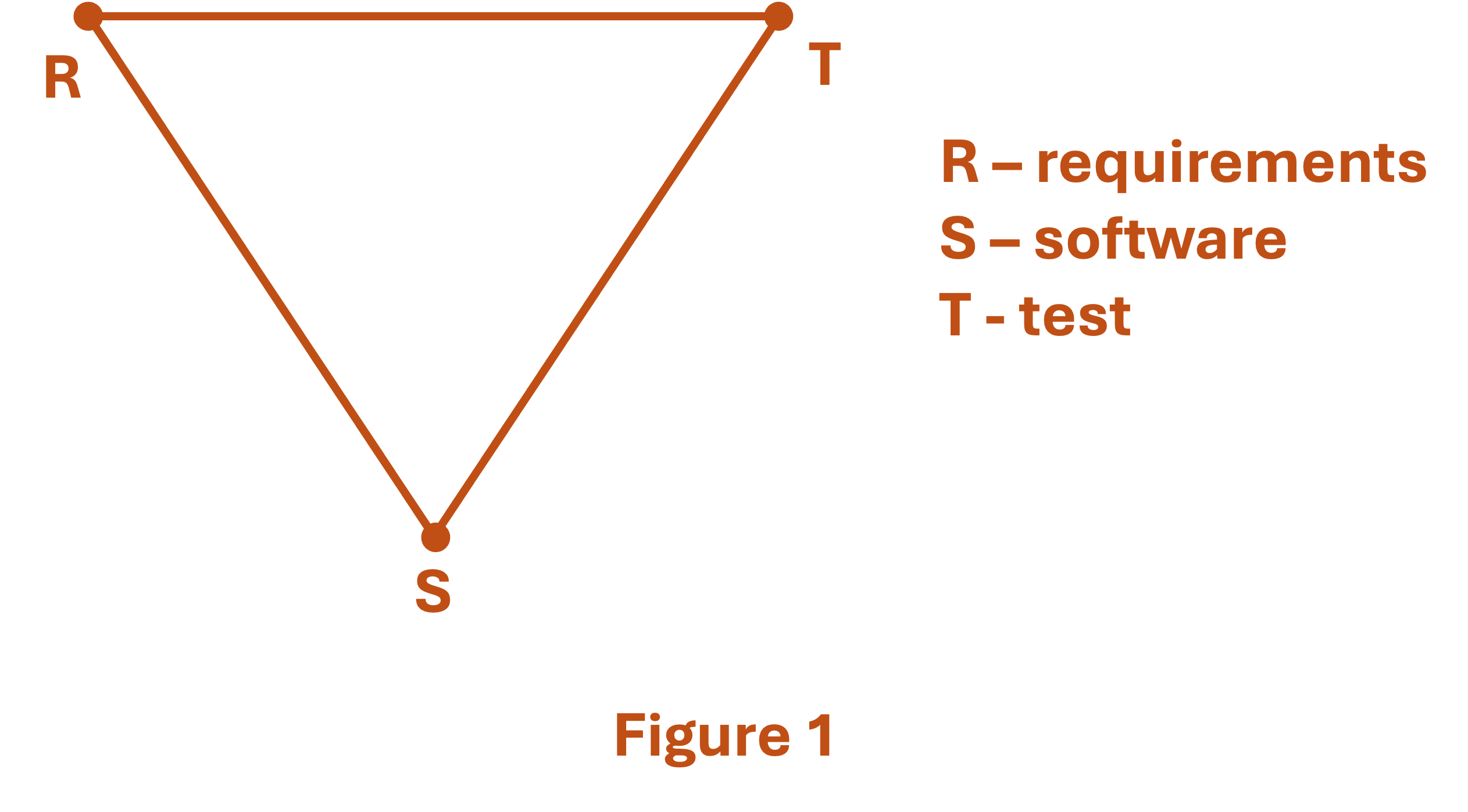
These three things are the bare-bones minimum set of information that must be defined in a software project: the software itself, the test information, and the requirements. These form the basics of the small-scale ‘V’ in the V-model, as shown in Figure 1. It’s a kind of triangle-offense for software and it’s super-simple. In fact even the most agile of Agile practitioners doesn’t typically push back against these three.
It’s Not Where You Start, It’s How You Finish
When software programmers go to do their job, many of them think along the lines that we just described. A software developer will think, “I’m writing code this week. I also need to test it. And I should have some requirements to guide me”. But when we read papers, standards, and frameworks for software development based on the V-model, we see a different order of operation. In V-model standards and frameworks, the requirements are defined first. Then the software is written. Then the testing is done. Linearly, always in that order.
And that’s where things come off the rails. Because the order proposed in standards and V-model frameworks is impractical. In many cases the requirements themselves are a bit unclear until we’ve dabbled with some code solutions, and maybe run a few tests. (Remember, software writing and testing is often a fast-turn process, not requiring weeks or months). Especially when requirements are discussed and debated for months on end, its just not practical to tell coders “don’t code yet.” Life doesn’t work that way.
To understand better, let us change our frame of reference to discuss a totally different task. Imagine a basic instruction set for preparing a meal at home. It might look like this:
Step 1: SHOP - go to the store and purchase ingredients
Step 2: COOK - prepare meal using ingredients according to the recipe
Step 3: EAT - consume the meal and provide feedback.
Are these instructions wrong? Not exactly. If you follow them step-by-step, you will cook and eat dinner. But you could never cook a weeks’ worth of meals for a family this way. Because in practice no one goes to the store to purchase ingredients every single time they cook. Shopping happens on a different cadence from cooking. Shopping and cooking have different goals, different constraints, requiring different skillsets. Shopping and cooking are just … different. When we tie shopping to cooking together in a single linear process, we are mistaken. Or maybe we’re just a bit naive. The linear model implied by the 1-2-3 order is a sign of immaturity in understanding.
However: shopping is related to cooking. We can’t cook without ingredients! The two steps are coupled, and the first step is necessary for the second. Just not in a linear and clean way; but in a nuanced and complex way.
Similar for our small software project: The requirements and the code are coupled; and the first step is necessary for the second. Just not in a linear and clean way; but in a nuanced and complex way. In fact “nuanced and complex” can feel like chaos in the moment, even on a well-run software project. A developer may write code, test it, realize a requirement has an issue, report the issue, and get the requirement updated or clarified within a 24 hour period. Multiply this kind of intensive iteration by several developers and several modules, requirements, and tests, and you get a chaotic kind of progress. Welcome to the modern, Agile, somewhat-frenetic software project. Figure 2 gives a graphical view of it. It’s still the same micro-scale V-model as described earlier. But inside the V there’s constant buzzing iteration.
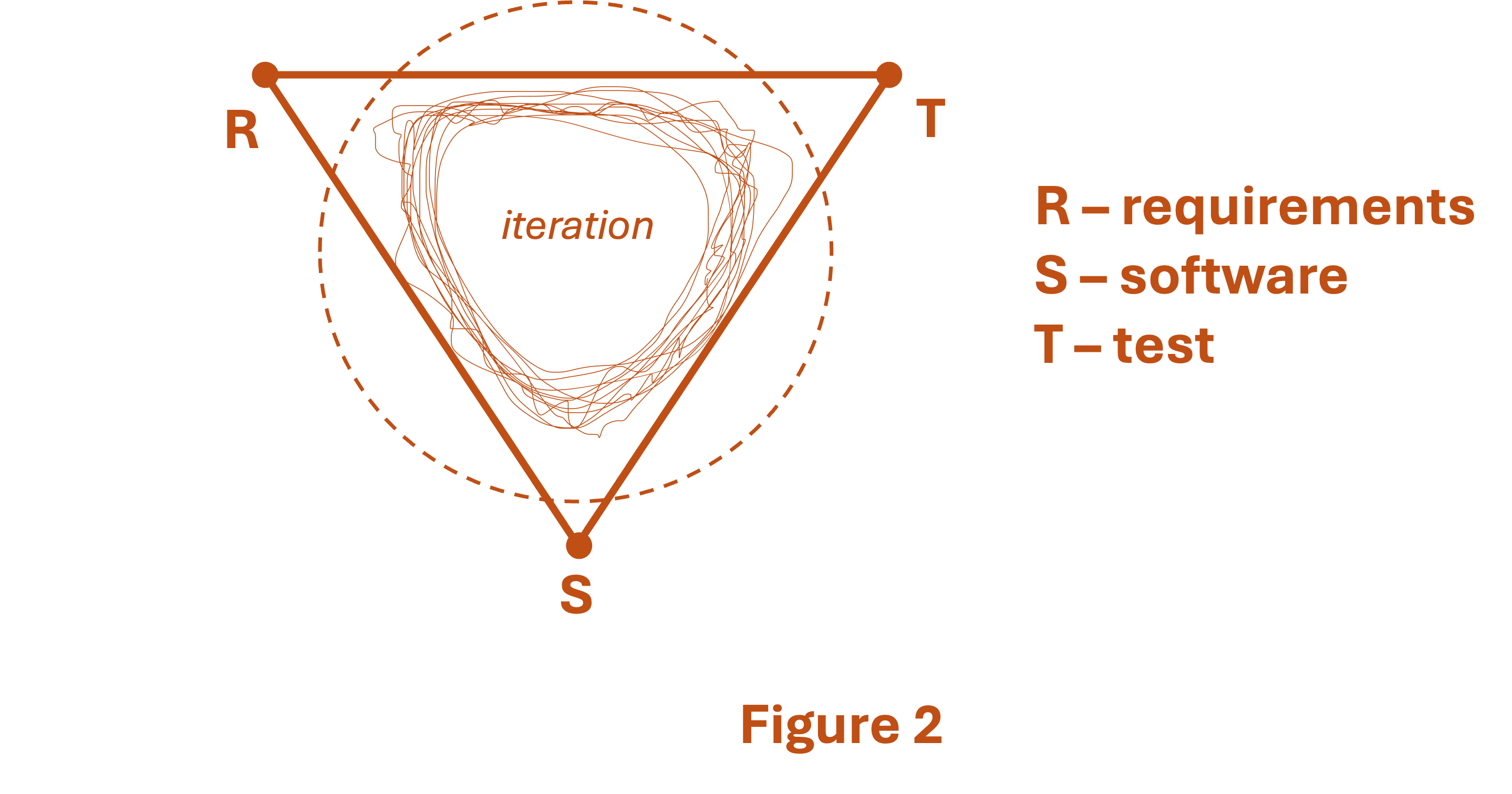
The goal of this messy “small V” is to deliver (at the end of some intense iteration and debate and rework and messiness… at the of all that, to deliver) all three minimal pieces of information; and for the three to be self-consistent. By “self consistent” I simply mean that
the test information reflects the requirements; and
the test information reflects the outcome of testing the code; and
the code meets the requirements (as demonstrated by test information).
That’s all. That’s the goal. It can be as hectic, as iterative and non-linear as it needs to be. But in the end, all three pieces of information should be delivered; and all three must be self-consistent. (If they’re not self-consistent, then we’re fibbing… we’re representing requirements that the code does not meet; or tests that the code does not pass, or requirements that the tests don’t cover).
Another way to think of this solution is to plan for concurrent delivery of all three pieces. Let it be messy. But deliver it all together, as a unified set of information, when you get to the end of a given stage (or phase or sprint, or whatever time unit you use). Implicit and critical in this point: don’t formally document every iteration. Consider all three pieces of information to be in flux, until the end of the sprint when they are completed and released, together.
It's true that software coders can’t be sure they’re on the right track until requirements are finalized. So there’s a risk of writing code to do the wrong thing; and needing to re-work it after the code is developed. My advice: don’t hang up the entire project on this potential issue, but instead manage it as a risk. Life happens. Deal with it.
Big-V Problems
Our “little V” is a good model for small software projects. But most software projects aren’t small. They’re big. In practice they consist of many little-Vs, run in parallel for multiple teams writing and testing multiple modules of code. Big projects require some coordination between these many evolving pieces of software. Therefore we need to re-ask the question: for large software projects, is any other minimal information necessary? Large projects tend to require a few additional pieces of information.
First: the developers working in the small-V need to understand what part of the larger software they’re writing; and how their piece fits into the whole. This requires a defined software architecture. Architectures are important because they define the overall system structure, and set some rules of the road for multiple teams working on a larger project.
In the same breath as these “architecture-oriented” parts of software, we would expect to have requirements from the systems level. These are typically “flowed down” into more detailed requirements at the software level. Figure 2 shows this on the “left side of the V” as it is known. And, just as we had a higher-level set of architecture and system requirements on the left, so too must we have system-wide integration and test on the right-hand side of the figure. It is also shown in Figure 3, on the right hand side.
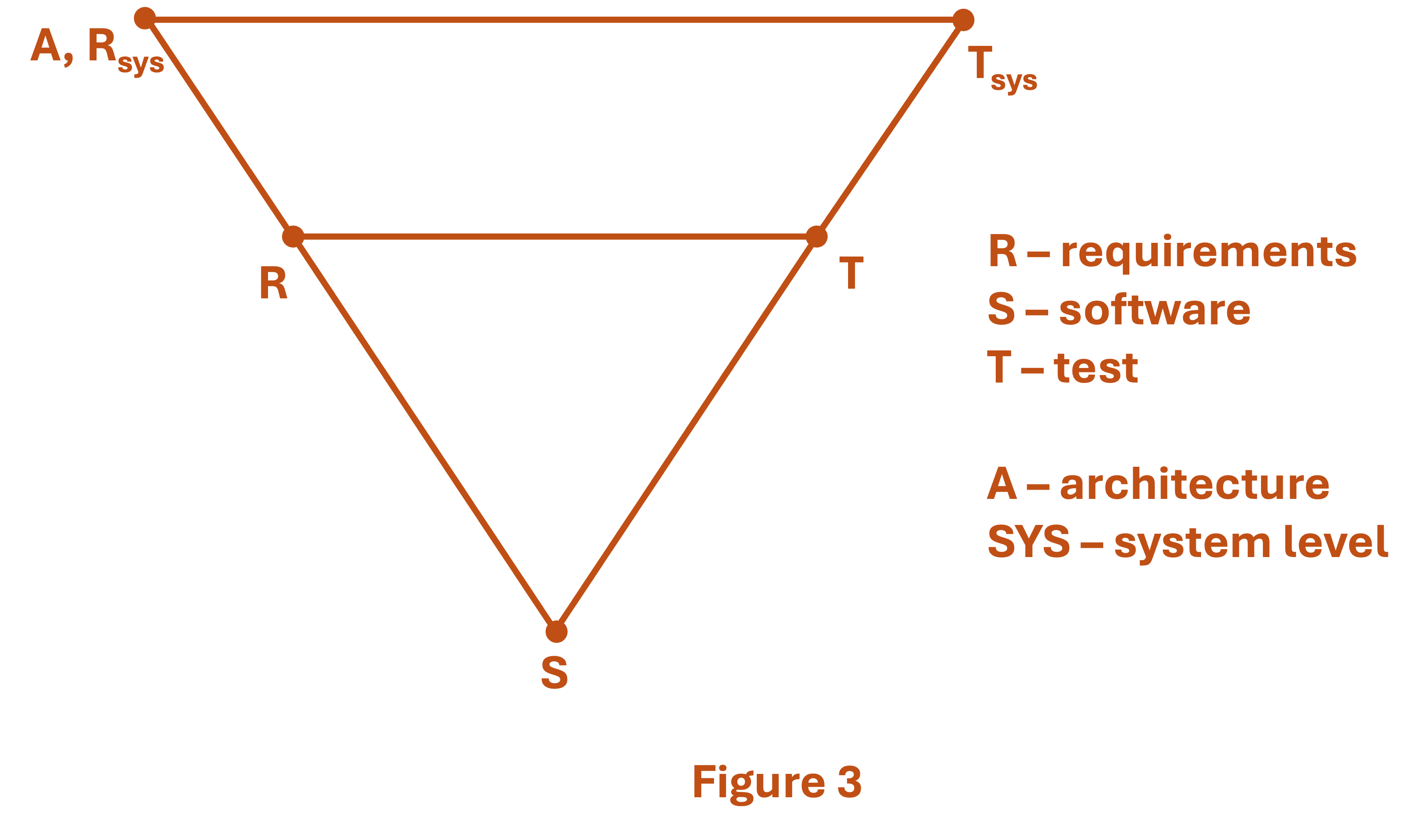
These higher-level system requirements, and the higher-level systems test to accompany them, create new activities; activities that relate heavily to software but which are not themselves software coding. Defining architectures, writing higher-level requirements, and specifying system-level V&V activities…. these are new, software-adjacent activities that are demanded in a larger software project. And these new activities create new headaches. In an agile world, we need some new solutions.
Wanted: Modular Architects
As discussed in Part 1 of this essay, a lot of V-model thinking was pioneered in cold war defense projects. In those hierarchical projects, designs flowed from the top down. The architect of such projects was comparable to the architect for a cathedral… a developer of a master plan, empowered to make sweeping decisions and enforce rigid rules, all in the service of maintaining a vision of perfection in the outcome. The architect ruled the roost. Each subsystem was optimized to meet the integrated architectural plan. This is an idea that aligns to integral architectures… custom-designed systems, optimized for purpose, developed by a deliberate plan. Big optimized mechanical things tend be this way. They’re top-down and integral by nature.
But as noted previously: modern software is not always developed top-down. It’s often developed bottom-up or sideways, as developers mix and match key libraries of existing code to achieve the needed outcomes. Modern codebases are networks of many libraries and some newly developed code, assembled with speed and flowing according to the intuition and effort of the programmer at the base level. Often this mixing and matching is itself the source of new ideas, new implementations and even new products. This is the idea of modular architectures: systems made of modules that can be updated relentlessly, reconfigured easily, and tested rapidly to ensure correct and reliable function.
In modular systems like this, integral architectures (and integral architects) get in the way. To architect modular systems, we need modular-thinking architects. The architects role in a modern system is less about demanding adherence to top-down requirements, and more about maintaining and enforcing consistency between assembled parts. That means knowing what interfaces will work cleanly, and what interfaces will not. It means mastering the complexities of APIs, data pipeline specifications, and other interfacing information that allows this multitude of software pieces to come together. In safety and security projects it means component qualification policies, to enable the use of pre-existing libraries. And it means test and validation strategies that can fully verify and re-verify requirements as software changes rapidly. Modern software architects need skills that fit with modern coders and Agile projects.
Continuous Change Means Continuous Testing
This topic deserves its own heading and its own write-up. But at this point, it’s not a new or novel idea. The idea is continuous integration and continuous deployment (CI/CD), an approach that makes use of testing automation and device connectivity to continuously update software. CI/CD is not trivially easy to accomplish, as it requires good test automation tools along with high-quality bug-free software units, strong regression testing, etc. But when it works, it enables Agile even in complex systems and large software projects.
CI/CD is widely practiced and not particularly exciting these days. But the rationale for CI/CD is novel, and important. We don’t do CI/CD just because we want to be fast. We do CI/CD because there’s no other way to manage the constant iteration happening across all the small-V’s across our wider project. Remember, all our smaller pieces of software are all churning, in these chaotic little-V iterations, all the time. How in the world can we manually test each one, and then additionally manually test all of them integrated together, with so much ongoing change? We can’t. With so much frenetic iteration happening in Agile development, CI/CD is not a luxury; it’s a necessity.
*
To summarize key points: we have defined six minimalist pieces of information that must be defined (and yes, documented) even in Agile projects. These are the requirements, the software itself, and test information for the ‘small-V’; and additionally architecture, system requirements, and system test information for the ‘big-V'.
And we have three proposed solutions to bridge the gap between V-model thinking and modern agile approaches. These three solutions are:
Iteration and Concurrent delivery of self-consistent information for small-V activity (where ‘information’ refers to requirements, code, and test information)
Modular architects focused on the interactions and interfaces between software parts, recognizing the value and necessity of libraries and other existing code bases
CI/CD approaches to automate the integration and test of software as it evolves.
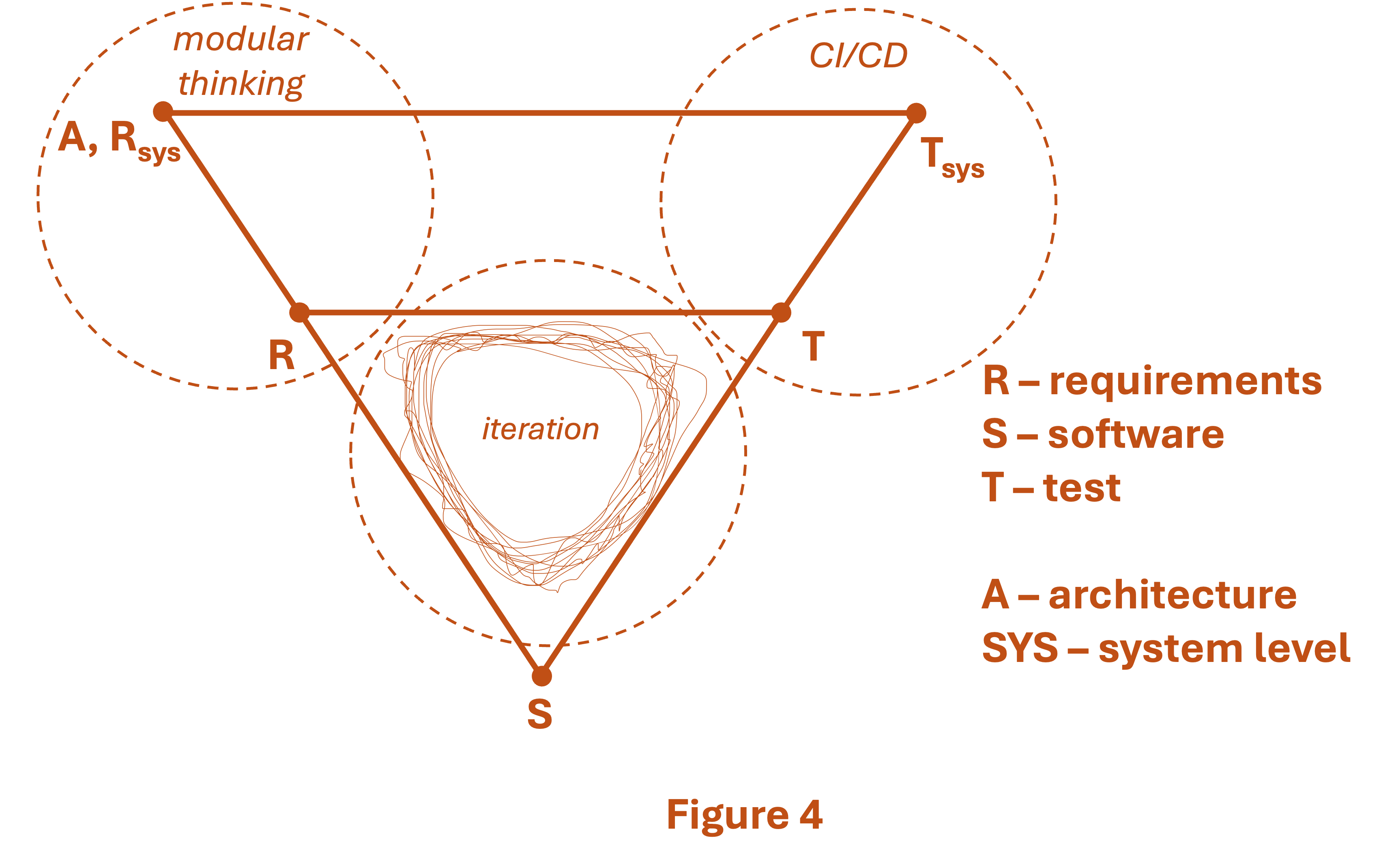
It’s worth noting that tool-based automation of quality steps are absolutely enablers for these approaches (and especially for CI/CD). If you’re going to test potential new releases every week, better make sure you can manage the relevant requirements and configurations for those releases. And especially if you’re in the safety business, better make sure you have test cases that truly cover those safety requirements. All the above requires documentation. Hopefully you have tools to automate that documentation, at least to some degree. Agile is fast; and manual documentation is slow.
Actually most things are slow first before they become fast later. All of which raises the question: is there stuff that can’t be Agile?
The Limits of Agile
Even with smart approaches, some things are just not attuned to the Agile world, and maybe never will be. Just as modern managers need to respect how developers do their work, so too must developers respect the less mutable and slower evolving parts of an overall system. So what resists Agile? A few things come to mind:
Hardware – For web-based applications running on server hardware, hardware can be largely abstracted. But not everyone has that luxury. Embedded systems still rely on tight coupling of processing and I/O capabilities with the code itself. Hardware evolves slowly…. You can’t built and test hardware overnight. And when you get hardware wrong, you’ve wasted a lot of time and money. Software developers must respect the slow-moving nature of hardware, and plan accordingly.
Emergent Functions and Validation – The nature of complex systems is that functions emerge within them. These emergent functions are the topic of intense academic study. We want to know how they work and how to control them! But in the end, the only real way to know about emergent function is to build systems and observe them. As a practical matter, this means that Agile-developed full systems often still require long-term observation and validation, as integrated systems running in their intended environment. “Long term” may mean weeks, months, or years depending on the application. Validation just takes time.
Human Beings – I’m still re-learning how to use my Apple TV remote-control, almost two years after I purchased it. By now the good folks at Apple have released new versions with better hardware and software. But I haven’t bought those yet; because I’m cheap and a bit lazy. That’s the nature of human beings. We’re set in our ways; we’re slow to evolve, and we don’t like change. Our software may be agile. We ourselves are not.
Finally, a word about quality. The approaches listed here are not rocket-science and can be implemented by any organization with some basic software competence. But basic software competence includes some quality measures that are non-negotiable. Version control and configuration management are must-haves, and they must be taken seriously. Common-sense measures like consistent bug-free tooling and development environments, static checkers for low-level bugs, code commit processes, etc., are all tickets to entry.
It's important to close on this reminder about quality. Because the word “Agile” is too often used as a fig leaf, to cover up the idea of “no process at all.” And that’s a shame. We’re all using processes, whether we admit it (or document it) or not. Make them Agile if you like. But don’t discard them. In the long-run, our processes are what we do with our days, our careers and our lives. Or in the words of Aristotle, “We are what we repeatedly do.” Develop accordingly.